
Oracle 1.22s timeout after packet retransmit on AIX server
I have an issue of slowness on an Oracle base after observing packet losses, but don't really understand how to pinpoint more between Oracle and the AIX server TCP stack.
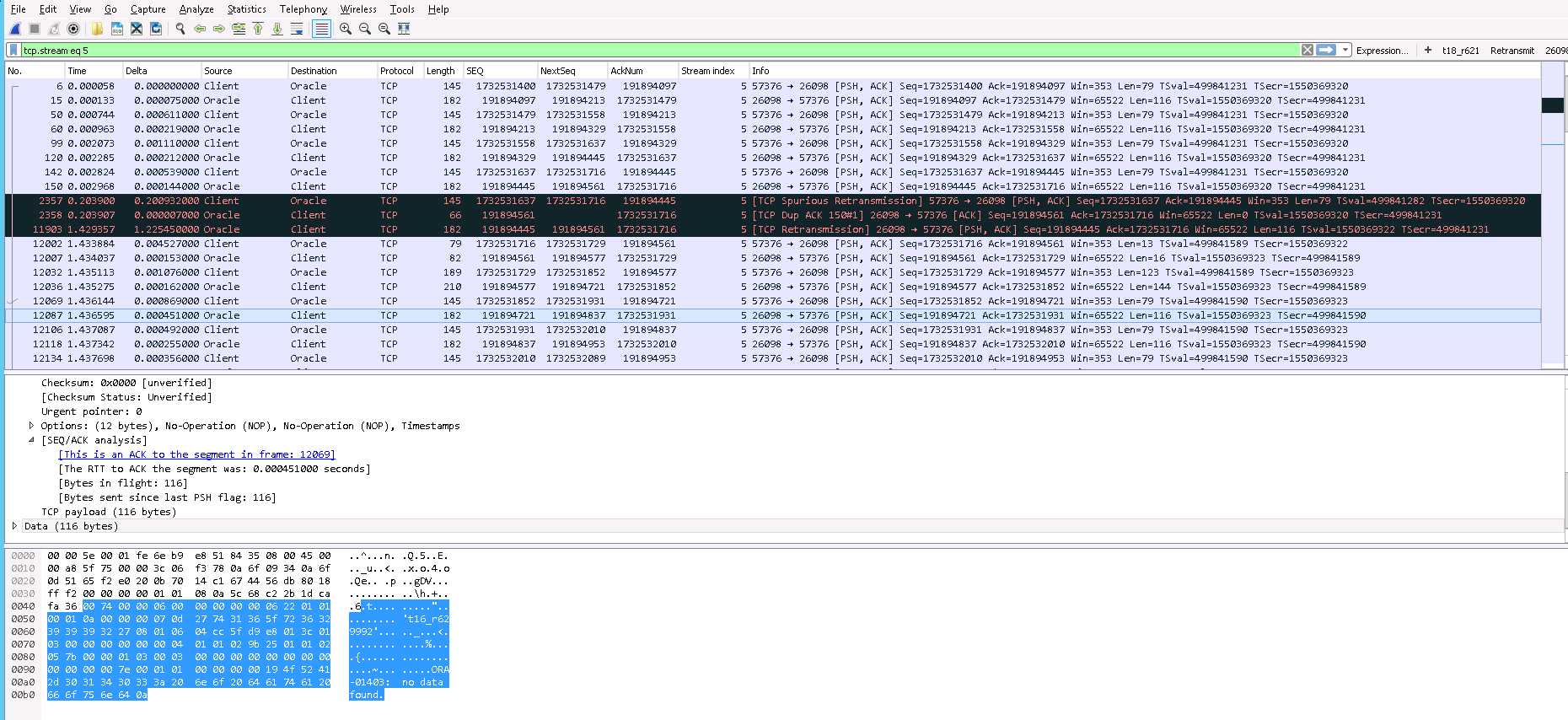
No pcap unfortunately, only this screenshot. Trace is taken with a tcpdump on the server.
TCP baseline is:
- Client sends request of 145 bytes
- Server answers with 182 bytes in less than 1ms
Sometimes, packets are dropped on the way back from server to client, in that case:
- Client sends request (#142)
- Server sends answer (#150) in 0.14ms
- After 200ms, client sends another time the request (#2357)
- Server acks immediately (#2358)
- After 1.22s, servers sends the answer (#11903), which is a retry of #150
1st action: identify packet drops on the network and lower them
1st conclusion of the 1.22 seconds: Oracle is responsible of this delay to reproduce a 2nd time the answer, and the TCP stack acks the 2nd requests so quickly, proving that it's not an AIX TCP stack problem, but an applicative one, and also presence of PSH flag in request.
But: Oracle logs show that Oracle is waiting for client for 1.5s and does only once the process of request in DB Retransmission of packet #11903 has the same sequence number that #150, so this means the packet #11903 is coming directly from the stack buffer, not a new answer of application.
So:
- Why would the stack immediately ack the request without data if it retransmit directly the packet after?
- Why would the stack wait for 1.22s before resending a packet it has in buffer?
- And more important: where should I troubleshoot more? Tracing the process between AIX and Oracle?
Thanks for any feedback, Thomas

{kind=link}
My first thought was why is the client just sitting there after 2358? The server has ack'd the data. Then I realized that the first (150) was an ack + answer, and the second (2358) was only an ack. Server never gets a next request, so it finally times out and retransmits the ack + answer. My question is; is packet 11903 coming from tcp as a standard retransmit, or from the application because Oracle expects the client to make a new request? I'll be honest, I'm not sure. I want to say L7 since L4 has already achieved its goals, but I've never seen an Oracle server do that before.
I don't think this is an answer, per se, so I'll just add my take as a comment here, but I suspect the problem is related to the bi-directional flow of data.
(more)Frame 142: The Client sends 79 bytes of TCP payload and expects an ACK of 1732531716 from the Oracle Server. This frame also serves as an ACK to the data sent by the Server in Frame 120.
Frame 150: Server ACK's the 79 bytes the Client sent in Frame 142, but also sends 116 bytes of data and expects a corresponding ACK to these bytes from the Client.
Frame 2357: The Client obviously didn't receive the ACK (Frame 150), and at this point has no idea the Server attempted to send data as well, so after a 200ms timeout, the Client retransmits Frame 142.
Frame 2358: The Server sees the retransmission of Frame 142 ...
@cmaynard. That 1.42 delta is what makes me think this is an Oracle issue vs. AIX. I agree with Chris, the tcp stack would have timed out much faster.
Yes, maybe it seems to be an AIX behaviour. https://books.google.de/books?id=lHTJ...
@TomLaBaude I would try to trace also next to the client side. To see both sides.