
Domain Client Restartup - Ultimate Challenge
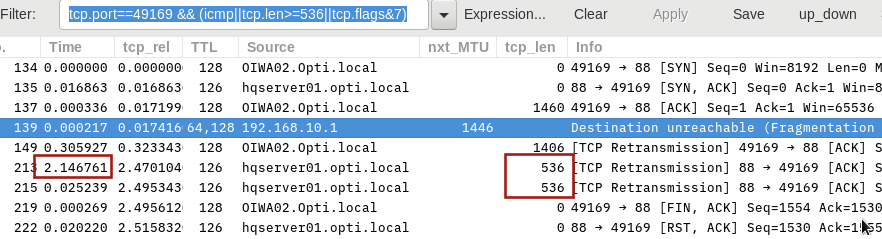
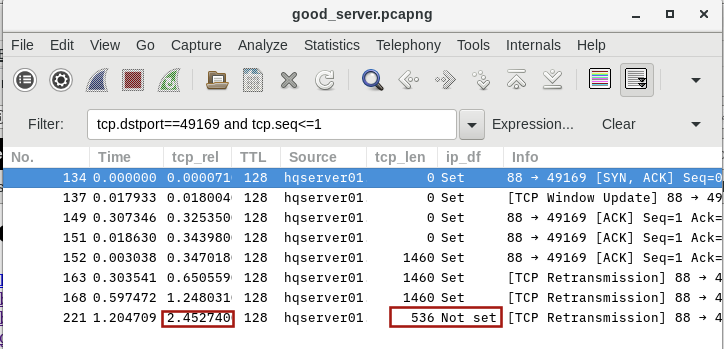
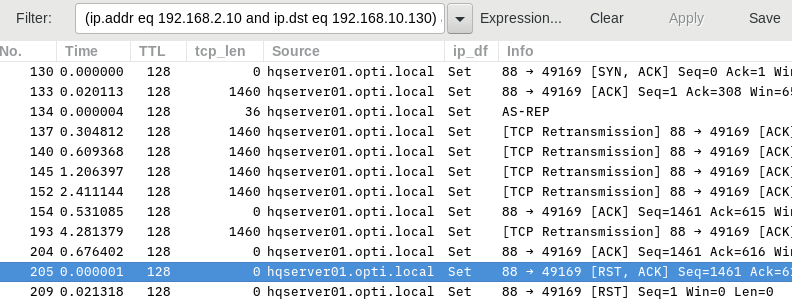
I have problem where client computers connect to the domain just fine. I can ping devices by name and by IP address and I can access shares. But randomly (it could be hours or days) I will lose access to domain resources such as shares. I can still ping devices, though. To fix the problem I have enter the current IP address as an exclusion in order to force the client computer to request a new IP address. Once the new address is assigned everything is back to normal. Restarting the computer does not fix the problem. I figured that the problem is that the computer itself losses authentication with AD. If I delete the DNS entry for the bad IP address the entry is not added when the computer is restarted. But once the computer gets a new IP address the DNS entry is updated. Therefore, I decided that troubleshooting should be focused on before the user logs in.
So I started to gather Wireshark captures. Since the client computers are in separate subnets from that of the Domain Controller I placed a capture computer in each subnet (one for the client and one for the server subnets). I gathered semi-synchronized captures from the bad IP address and from the good IP address. Since I don't have enough points to upload files here is the link to the files
http://teknacion.com/wireshark
Thank you very much in advance. Let's see who is the first to help me solve this mystery.
{kind=link}