
Im using Wireshark in Manjaro and i am testing a device with SLCAN protocol. If i am unsing candump from can-utils everything is fine. But if i want to monitor my data in wireshark the CAN identifieres are in wrong order like this: Wireshark: Ext RTR Err Byte7 | Byte6 | Byte5 | Byte4 | Byte3 | Byte2 | Byte1 | Byte0 CAN-Frame: Byte1 | Byte0 | Byte3 | Byte2 | Byte5 | Byte4 | EXT RTR ERR Byte7 | Byte6 Has anyone an idea if this is a wireshark slcan or socketCAN issue?
asked 13 Jun '16, 06:51 casartar edited 14 Jun '16, 00:10 showing 5 of 9 show 4 more comments |
One Answer:
Libpcap was specifying a link-layer header type of "SocketCAN with a big-endian CAN ID/flags field" for all captures, but only when capturing on a PF_CAN/SOCK_RAW/CAN_RAW socket was it put in big-endian form; the others provided it in host-endian form. I've 1) checked changes into libpcap to add a new link-layer header type of "SocketCAN with a host-endian CAN ID/flags field" and use that for all forms of SocketCAN-header packets other than the ones where it's explicitly byte-swapped and 2) checked in changes to Wireshark (master, 2.2, and 2.0 branches) to handle both of those link-layer header types and to add a "byte-swap the CAN ID" preference to handle older captures. answered 19 Aug '16, 16:46 Guy Harris ♦♦ |
Ideas come much better with a capture file open in front of you :-)
So unless it is a top secret, please publish (login-free) an example of such a captured file somewhere (Cloudshark is the place preferred by the community here but any file sharing service will do) and edit your question with a link to it.
It's not a capture, it is a screenshot, but if I understand it right there is an issue not with the order of bytes inside a CAN packet (which would be a dissector-related question) but with the order of the packets themselves, which is a capturing method related question. So what hardware & driver do you use to capture the CAN communication and how is it interfaced to Wireshark?
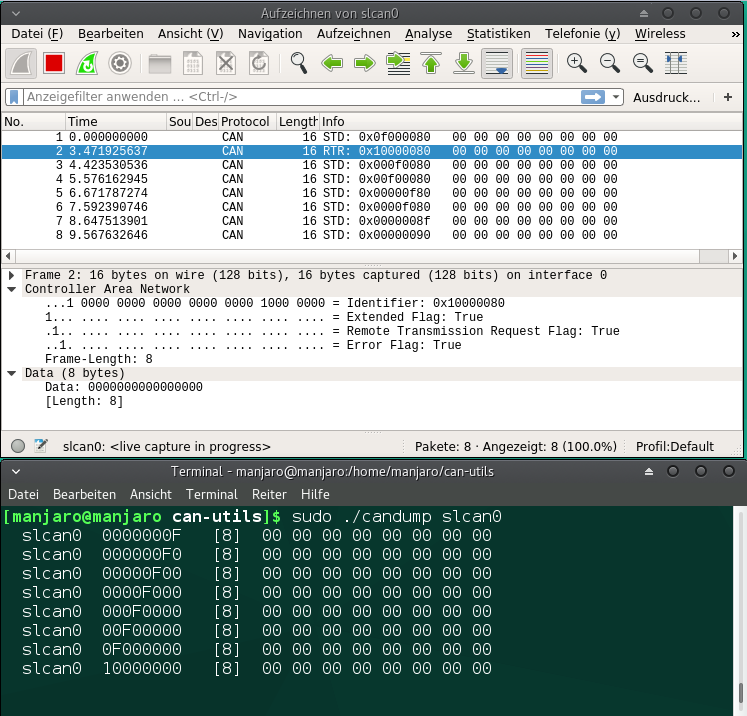
No its not a problem of the order of packets. Thats perfectly fine. The problem is the order of nibbles in the CAN Identifier. In Wireshark it seems the Identifier is represented by a 32-bit variable. A CAN Identifier has 11 or 29 bits. Bit 31 in the wireshark representation contain the additional information if it is an extended identifier (29 bit) or a standard identifier (11 bit). Bit 30 contains the information if its a remote frame. Bit 29 contains the information if its a error frame.
I have sent only Extended Frames. Data Bytes all 0x00. In the first message i have set nibble 0 of the can identifier to 0xF. In wireshark nibble 6 was 0xF. In the second message i have set nibble 1 of the can identifier to 0xF. In wireshark nibble 7 was 0xF (there are the additional frame informations in wireshark)
And so on...
My hardware is custom and im implementing the Lawicel/SLCAN protocol. It is a serial ASCII protocol.
I'm using the SLCAN kernel module which is the interface between the serial interface and SocketCAN
I'm still confused by the pictures.
I've thought that the two screenshots are from the same actual sequence of CAN frames, which is why I've thought that the frame order is wrong (because the
Fis travelling a different path in the Wireshark screenshot than in the can-utils picture).And I wanted a capture file rather than a screenshot because one thing is the order of the fields in the packet dissection pane (the middle one) and the other thing is their order in the packet bytes pane (the lower one which is missing on your screenshot).
If you click a row in the dissection pane, the corresponding bytes in the packet bytes pane get highlighted. So to see where the issue comes from, I need to compare the order of the bytes in the packet bytes pane with the can-utils capture and with the dissection. This should tell whether it is an issue of endianness (byte order) when generating the capture
filestream or an issue of the dissector.I finaly managed to get a capture file from wireshark (at least i hope so) https://www.cloudshark.org/captures/11a2cb7ff337
The screenshots are from the same actual sequence of CAN frames. The frame order is okay. Its just the nibble and byte order in the CAN identifier which is not correct.
I thought about the endianness but it would not explain way the nibbles in one byte are switched.
To me the nibbles do not seem swapped:
slcan:
Wireshark (or rather capture file contents):
So if you revert the order of the first four bytes (which means if you change their endianness), the nibbles stay at their places, because endianness affects only bytes, not the bits inside them. Order of bits is a difference between "telecom" (most significant bit first) and "datacom" (least significant bit first) serialization and thus is in most cases only interesting on the wire. Exceptions exist but they are mostly related to processing telecom frames using packet network means and correction of bit order is normally part of such setup.
Wireshark always shows the packet contents as it is stored in the pcap file (or as it was coming to its input). Respecting the endianness of multi-byte fields is a matter of the dissector, not of the capture. So here, the dissector assumes network order (MSB first), but the first four bytes were arriving to the input in intel order (LSB first). What does the CAN specification say about the endianness of this 4-byte field?
Same problem here on Arch Linux, amd64 architecture. Endian conversion of first 4 bytes makes Wireshark display identifier correctly, I used "edit packet" feature to confirm.
E.g. "df 07 00 00" --> "00 00 07 df" did the trick.
Makes useless text in column info "RTR: 0x1f070000" to "STD: 0x000007df" which is correct and filters (can.id==0x7df) now work as well. Haven't used Wireshark before but there are older(?) screenshots where Wireshark was doing good:
Article http://skpang.co.uk/blog/archives/1141
screenshot: http://skpang.co.uk/blog/archives/1141/wireshark1
After studying some more SocketCAN stuff my current conclusion is that the Wireshark component for parsing SocketCAN canid+flags (first 4 bytes) somehow assumes wrong endianness. Big endian instead of native?
Probably nothing to do with SLCAN device as data source since standard can-utils (cansniffer, candump) always show correct data. I am using original CANUSB device and standard Linux slcan kernel module.
Neither kernel SocketCAN txt document nor include file can.h specifiy any endianness at all.
Excerpt from can.h:
Libpcap, when capturing on a PF_CAN/SOCK_RAW/CAN_RAW socket, puts the
can_idfield in network byte order - big-endian - so thecan_idfield in a pcap or pcapng file should be in big-endian byte order, regardless of whether you captured on a big-endian or little-endian host.If the capturing isn’t being done by Wireshark (or TShark or dumpcap or tcpdump or any other program using libpcap to capture traffic), and whatever program is writing the pcap file isn’t writing the
can_idfield in big-endian form, that program is buggy and needs to be fixed.