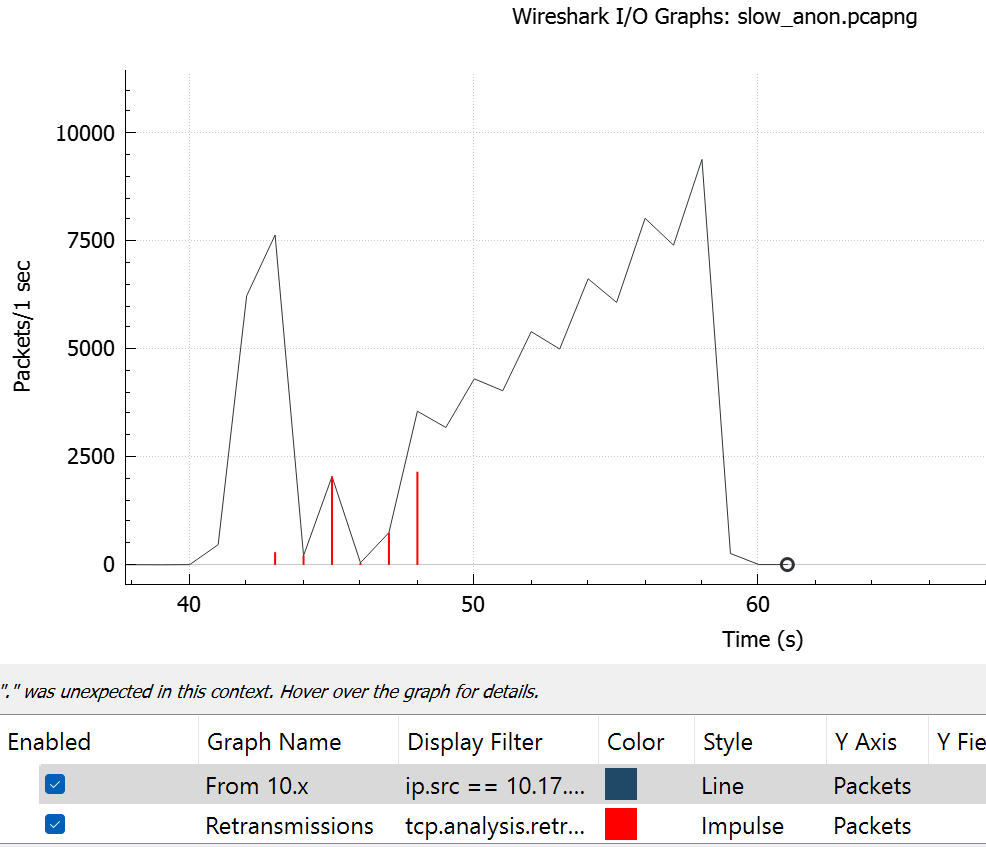
slow transfer in one direction
Hello i have two sites connected via SDWAN. Checked SDWAN side and dont see any issue from profile or bandwidth control wise. but for some reason site A to Site B is fast and site B to Site A is slow.
slow transfer https://drive.google.com/file/d/199Rf...
fast transfer https://drive.google.com/file/d/17h8K...
couple of things, i have anonymized both copy for security reasons. I am transferring same file in both directions via SMB.
Also i have capture right outside of one of the server. So MSS might show as a 1460 in fast capture vs 1320 on slow capture but please ignore that part due to the location of teh capture.. it shows like. that. MSS is 1320 in both direction due to sdwan overhead.
significant retransmission and out of order packets on slow transfer..
and i don't have both side of the capture right now..
please let me know if you see something pops out..
thanks