
macOS SMB uploads to Windows Server share hang for dozen of seconds
Update #1 : Server is not Windows Server but directly a NAS PowerScale Dell/EMC - OneFS OS v8.2.2
Update #2 : A sliced trace with 78 bytes is available here : Deleted
Update #3 : New trace sliced dynamically after TCP header by @SYN-bit (previous fixed slice at 78 bytes was cutting TCP header in case of several SACK blocks, leading to confusion) https://iwaxx.com/stuff/Transfert-Mac-ko-anon.gz.pcap
Good old TCP analysis guys !
Context :
1st quick troubleshoot at a customer, not all traces are ok, not all info from them, but I'll go back for them
The problem :
- On some specific sites only (private optical fibers between sites in same city : iRTT is 0.2 ms in this example, and always inferior to 1ms)
- macOS 10.15.7 uploads of a 40GB folder to a PowerScale NAS share hang for dozen of seconds or even stop with an error
- Downloads seem to be fine on macOS
- Windows 10 clients don't have any problem
- Server is a NAS PowerScale (ex-Isilon) Dell/EMC - OneFS OS v8.2.2
First analysis :
- Upload to server, trace is made directly on client
- iRTT is 0.2ms
- SACK permitted on both sides
- Timestamps enabled on both sides
- Client window size coeff : x128 (max: 8MB)
- Server window size coeff : x64 (max: 4MB)
- Network is loosing packets for sure, looks like burst in switch -> will investigate that appart
- My question here is on the difference of TCP behavior of the server & between Windows and macOS.
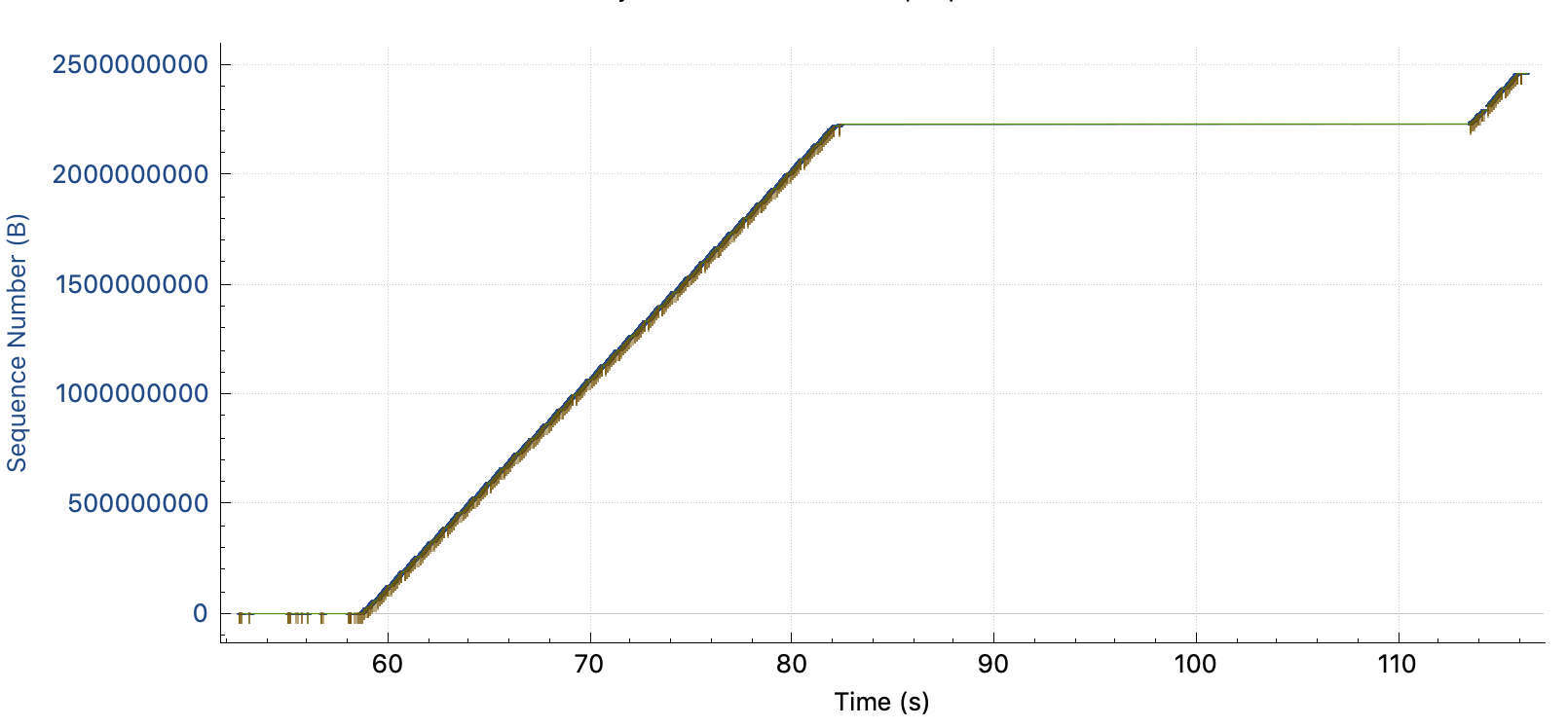
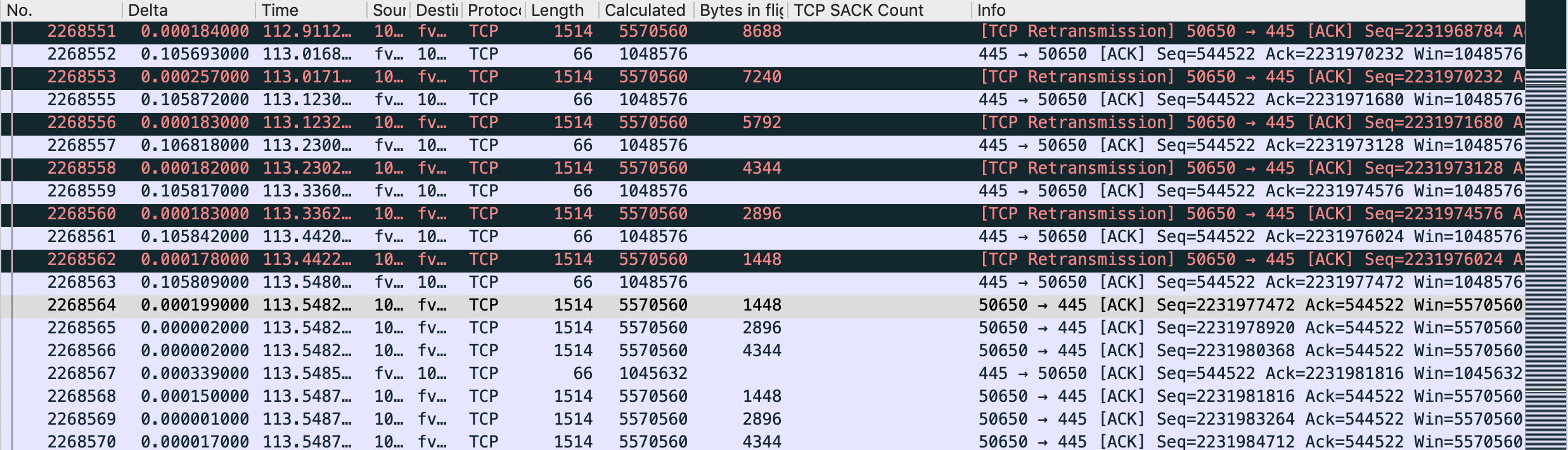
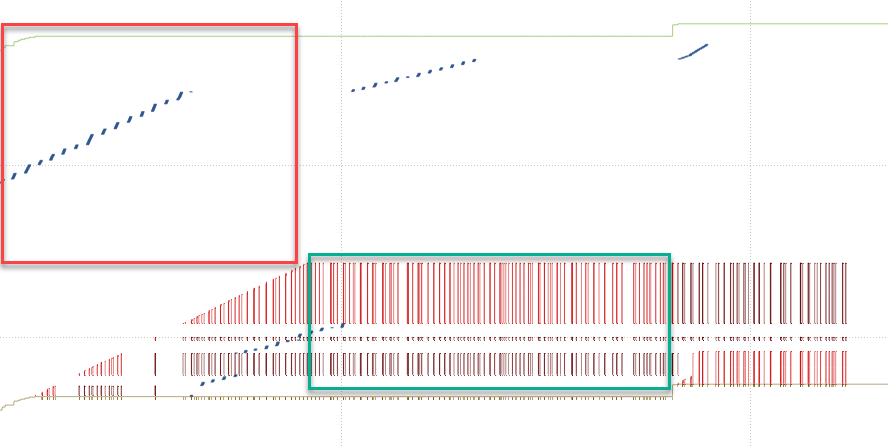
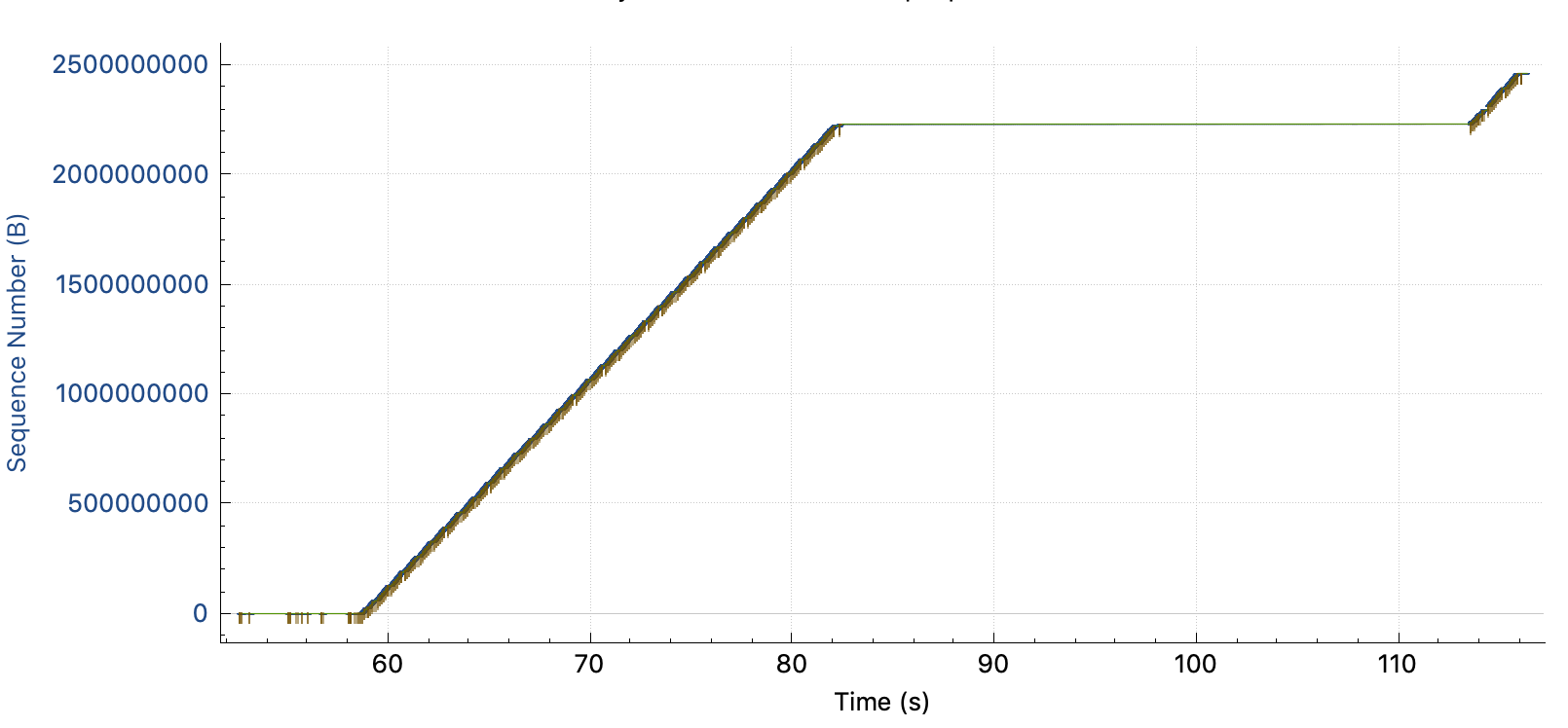
Just before the problem, status is :
- SACK is working
- NAS server window size : 1MB (since the begining)
- Client opens window size at 5MB
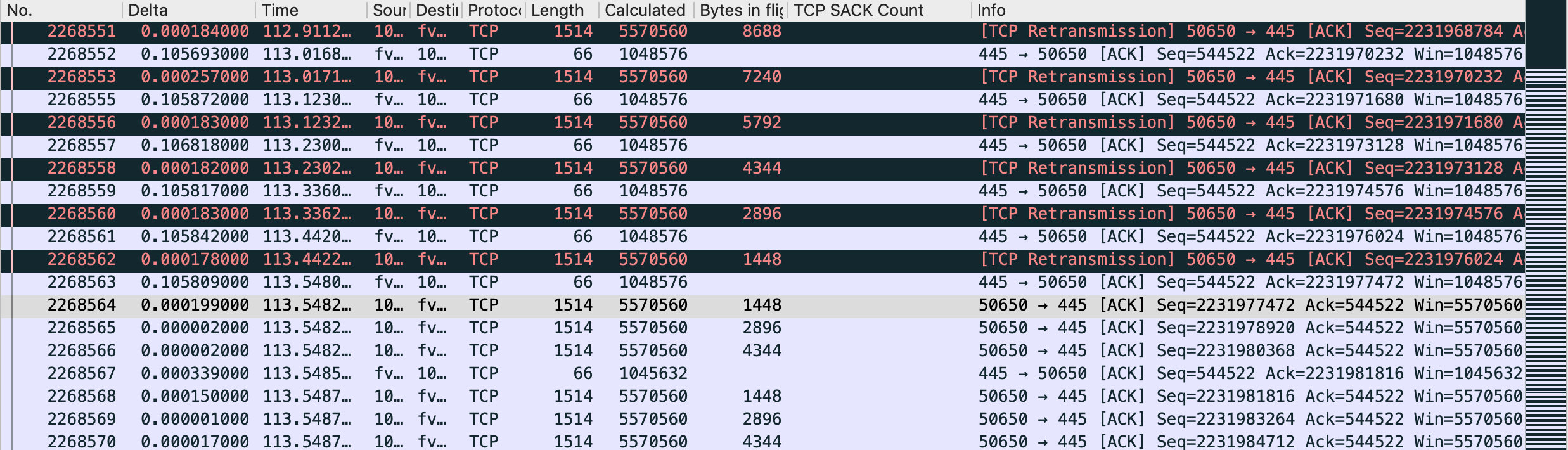
- Windows size is not full (bytes in flight: 725kB)
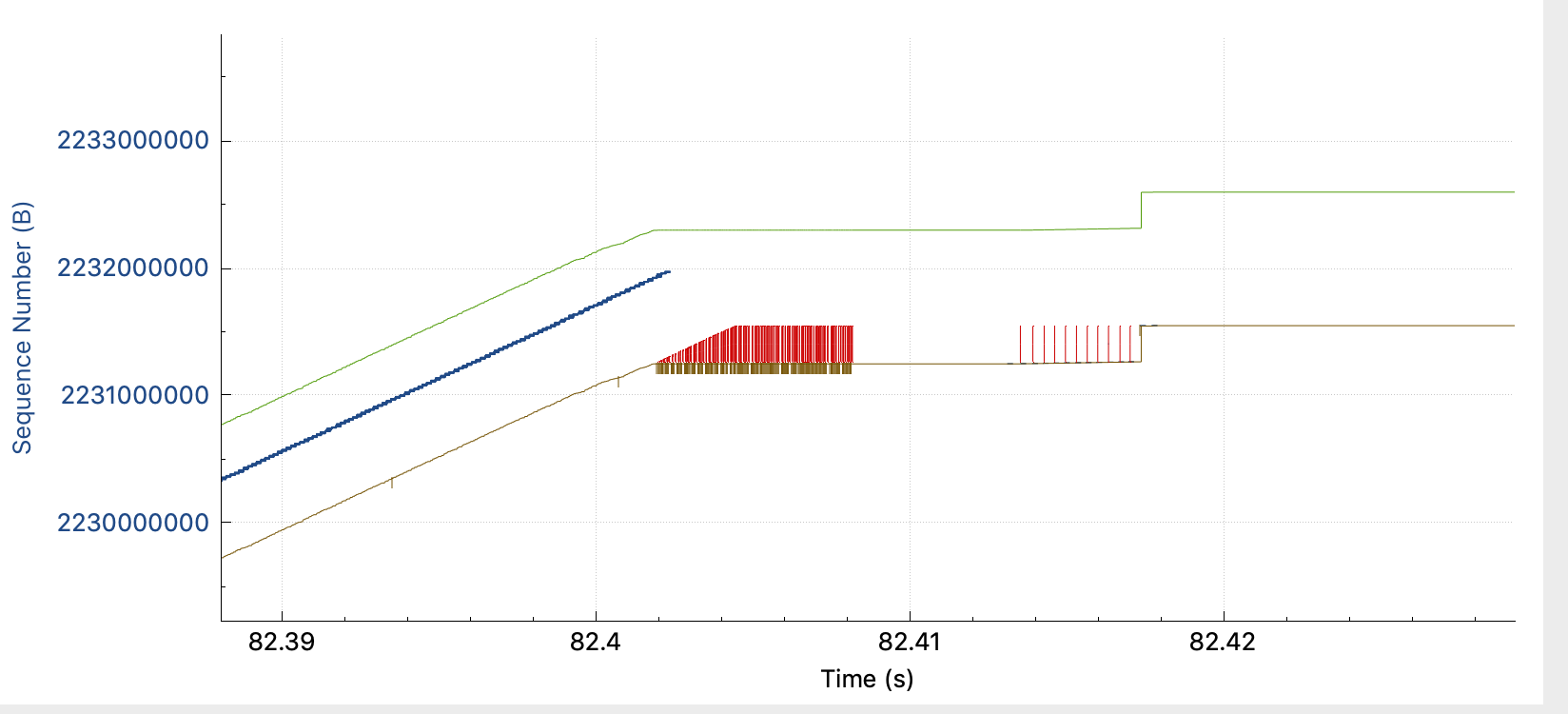
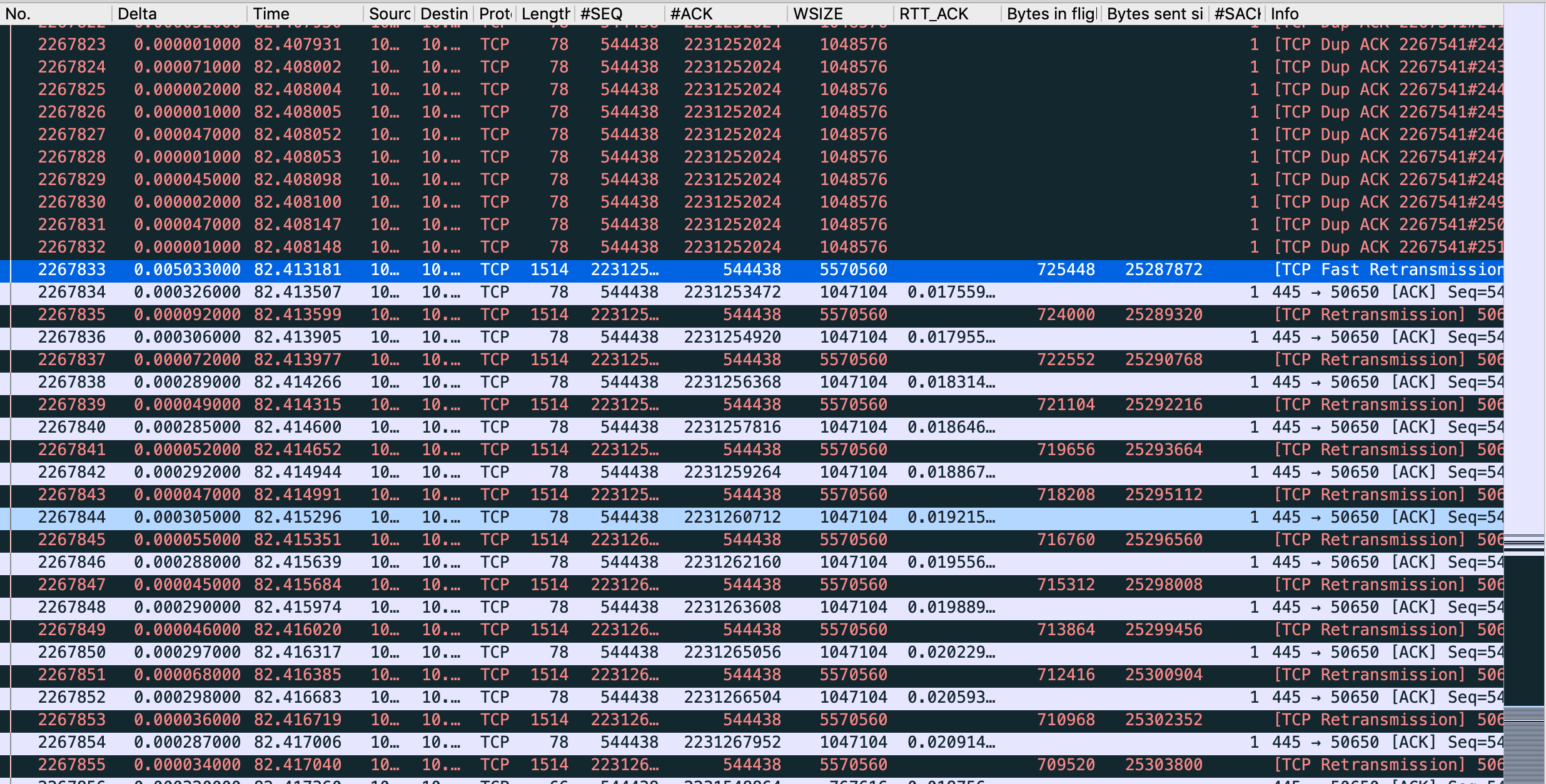
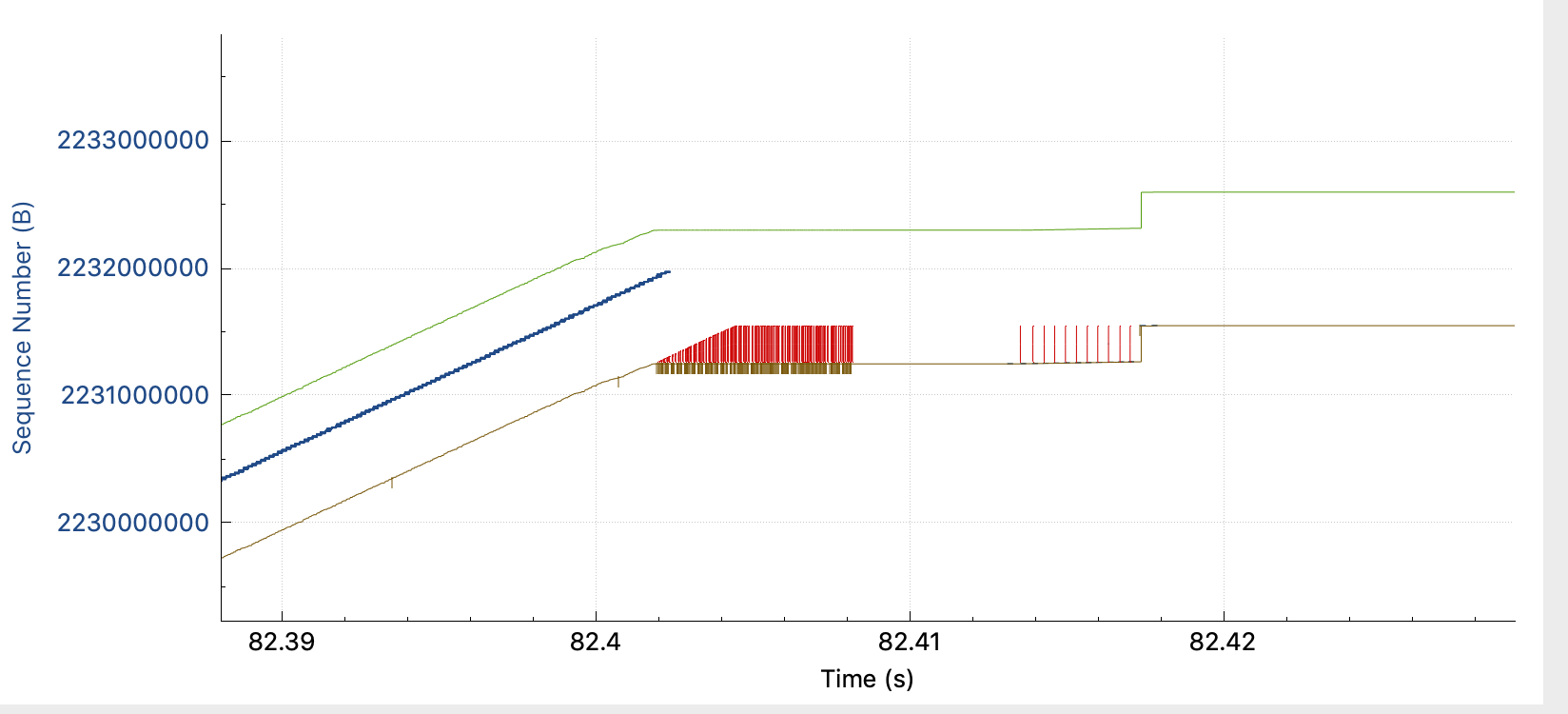
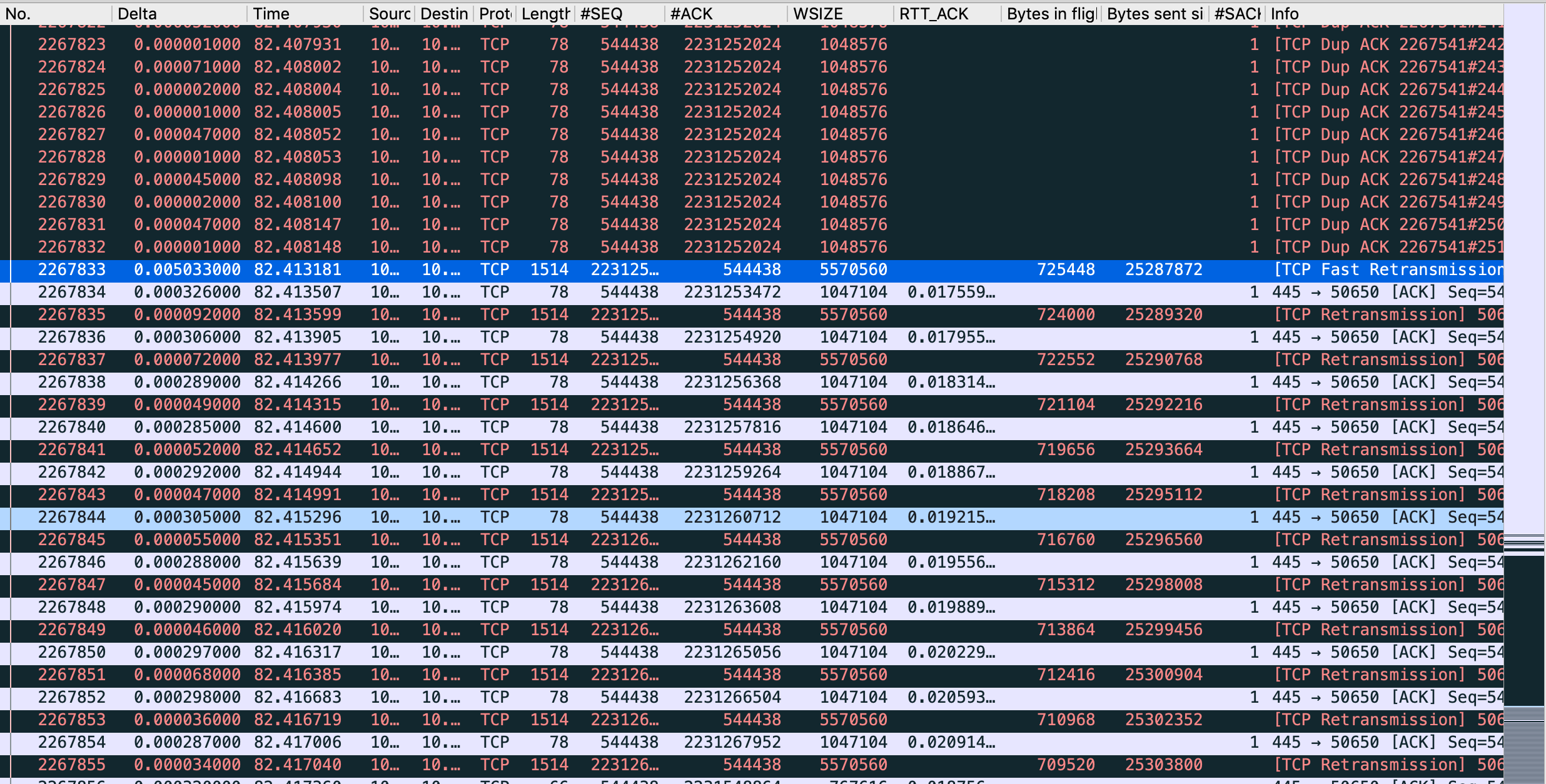
- At 82.41s, macOS starts to send missing packets 1 by 1. (Before, he's used to retransmit several of them)
- Server is acking them in iRTT time
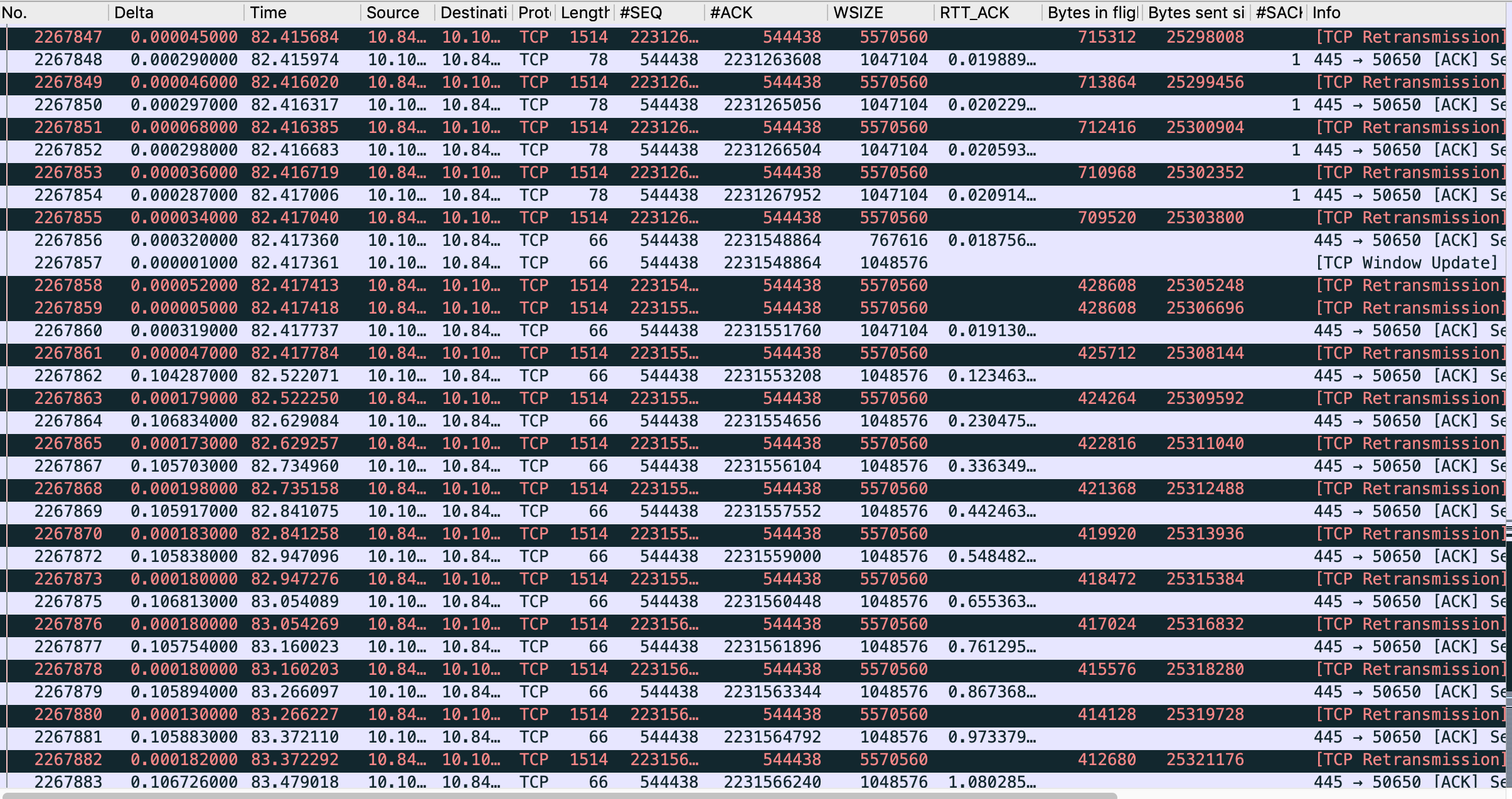
- At 82.522, after a few 1 by 1 retransmitted packets, acked immediately, it looks like the server is saying this rule : "Now, you gonna pay me every bytes currently in flight, but I impose a static 105ms delay in ACK."
- Then the long seconds, consists of Retransmit + ACKed in 105ms + Retransmit + ACKed in 105ms ... till all bytes in flight are ACKed.
- At 113.548, uploads starts again at full speed
My question about :
- Sending packets 1 by 1 makes sense on server side to reduce congestion window to 1 MSS
- But the 105ms delay from server before acking -> is it a known "congestion" behavior ? Or kind of slow start ?
- It looks to a consequence of a behavior of macOS to send packets 1 by 1 (supposition to understand next question)
- Why would this behavior would happen only on macOS and not Windows clients ? Knowing that same packets losses are experienced by macOS and Windows Clients (and Windows servers)
- Could it be due to SACK ?
Screenshots attached in case inside pics are not ok :



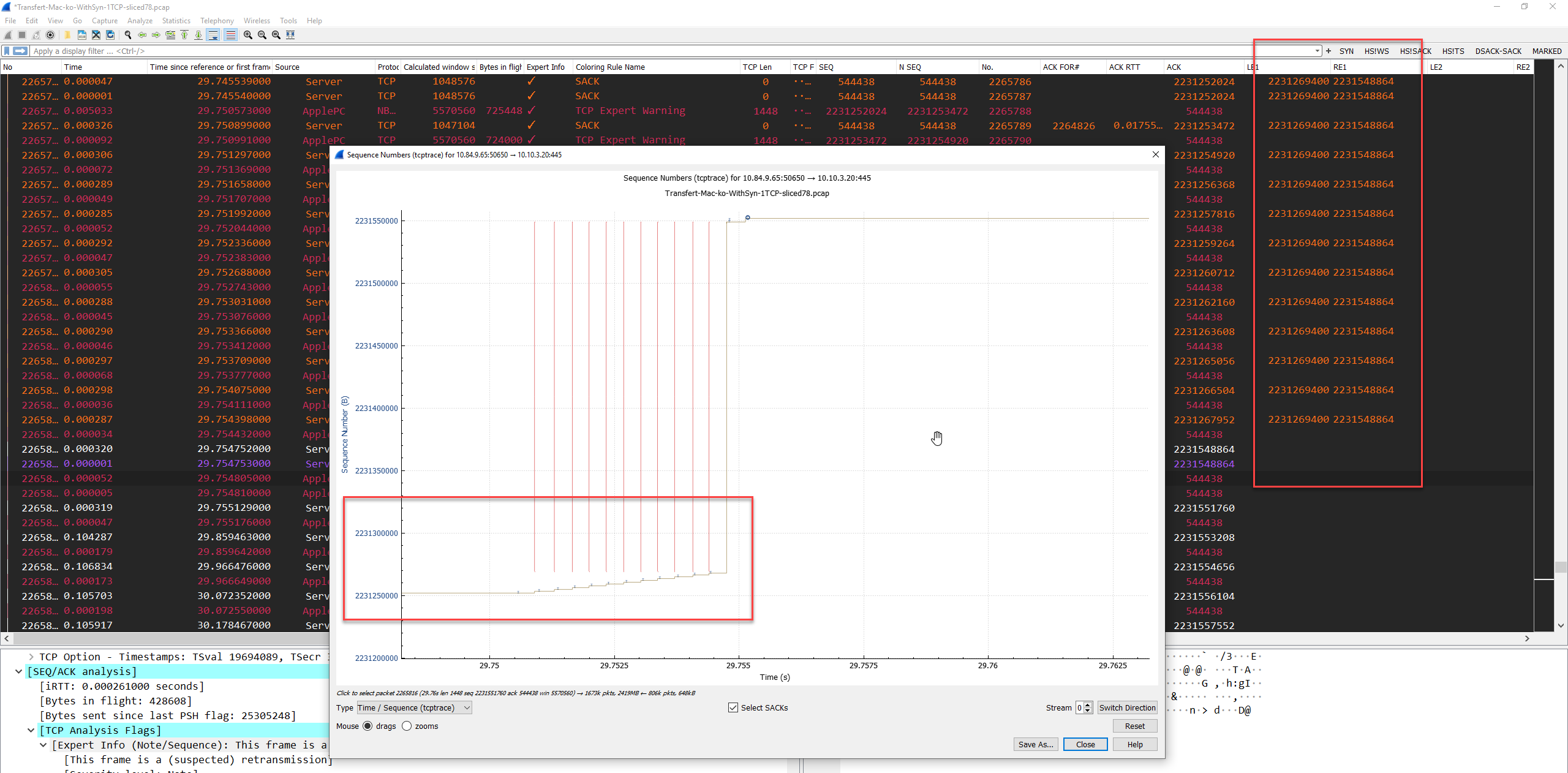
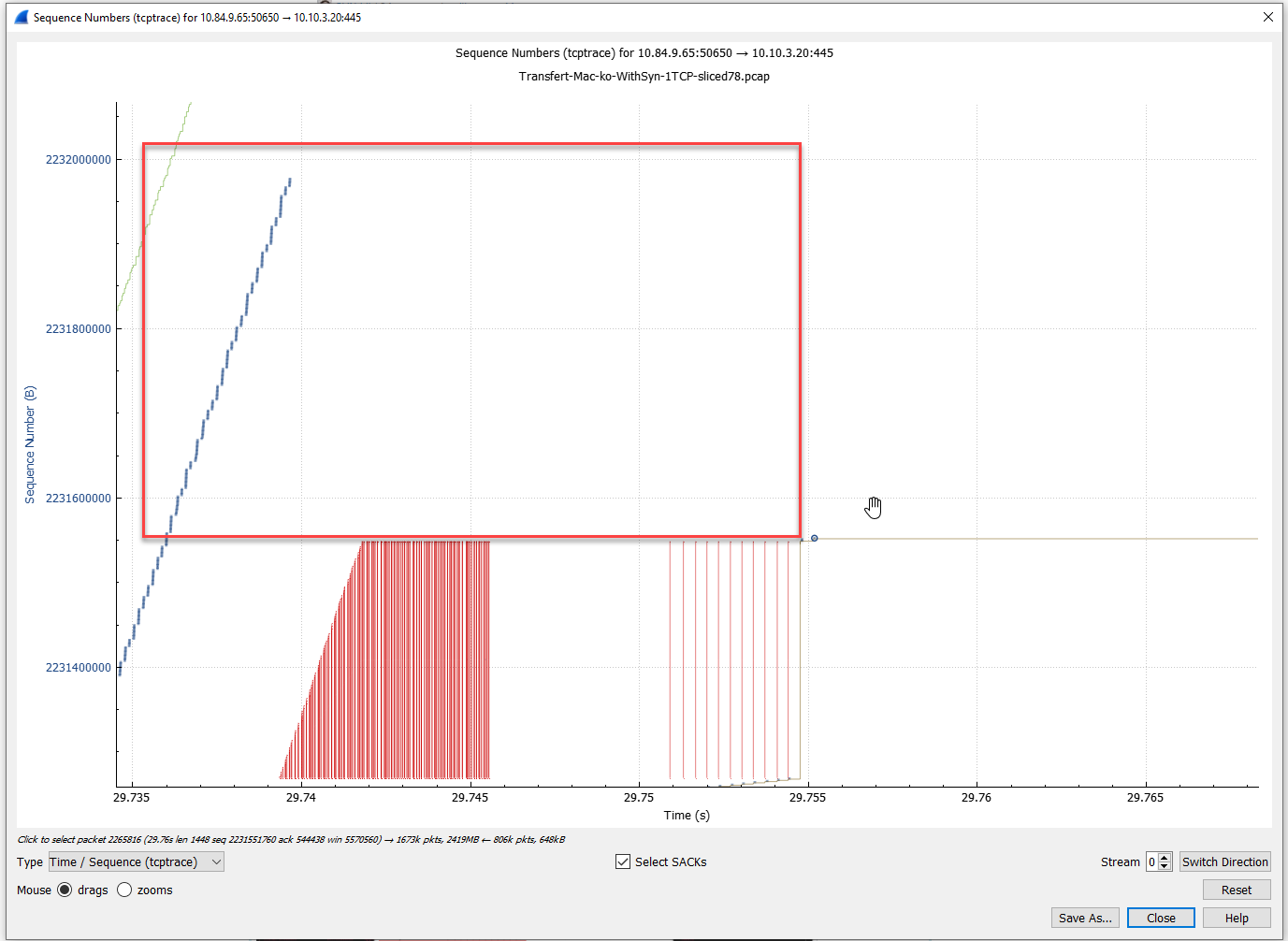
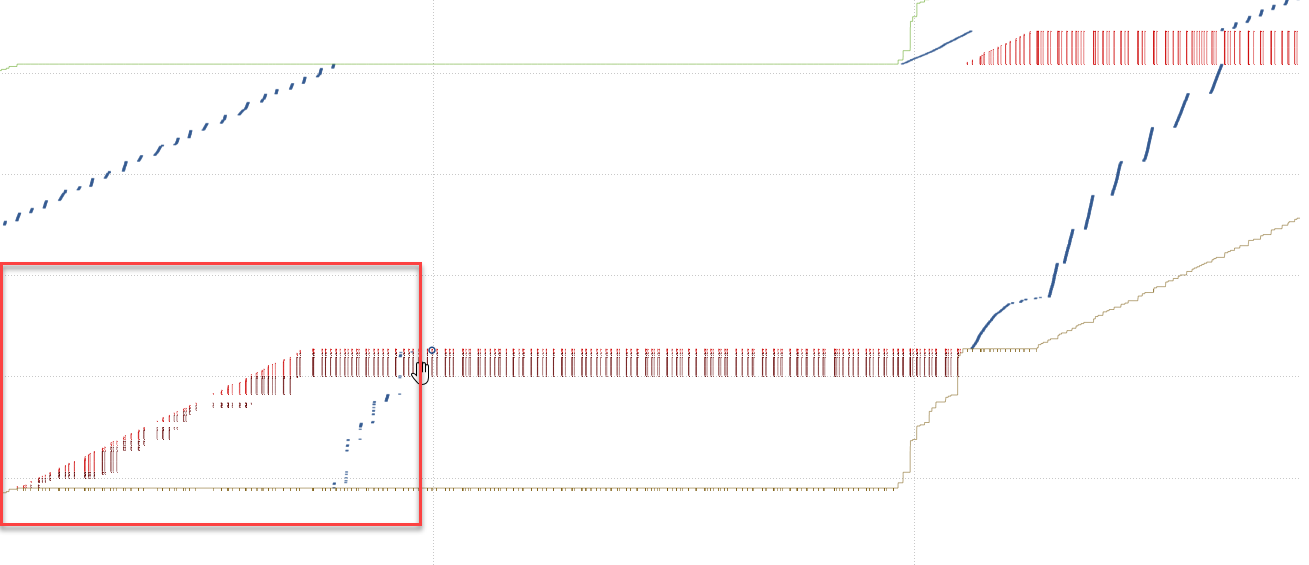


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi Tom
A wonderful mystery! Could you share a few more details:
And the most important detail, the (sanitized) pcaps?
@SYN-bit: I fully agree.
@TomLaBaude we need a sanitized pcap!
Sending packets 1 by 1 makes sense on server side to reduce congestion window to 1 MSSCould be part of data recovery algorithm...
But for better guessing I would need a look in the trace file.....
It would also be interesting, to have a comparable Windows trace. Because my personal feeling, at least in my private network (not proven by a trace) is that MacOS has a higher SMB throughput than Windows.